Visualizaciones
Selecciona un análisis para explorar los resultados.
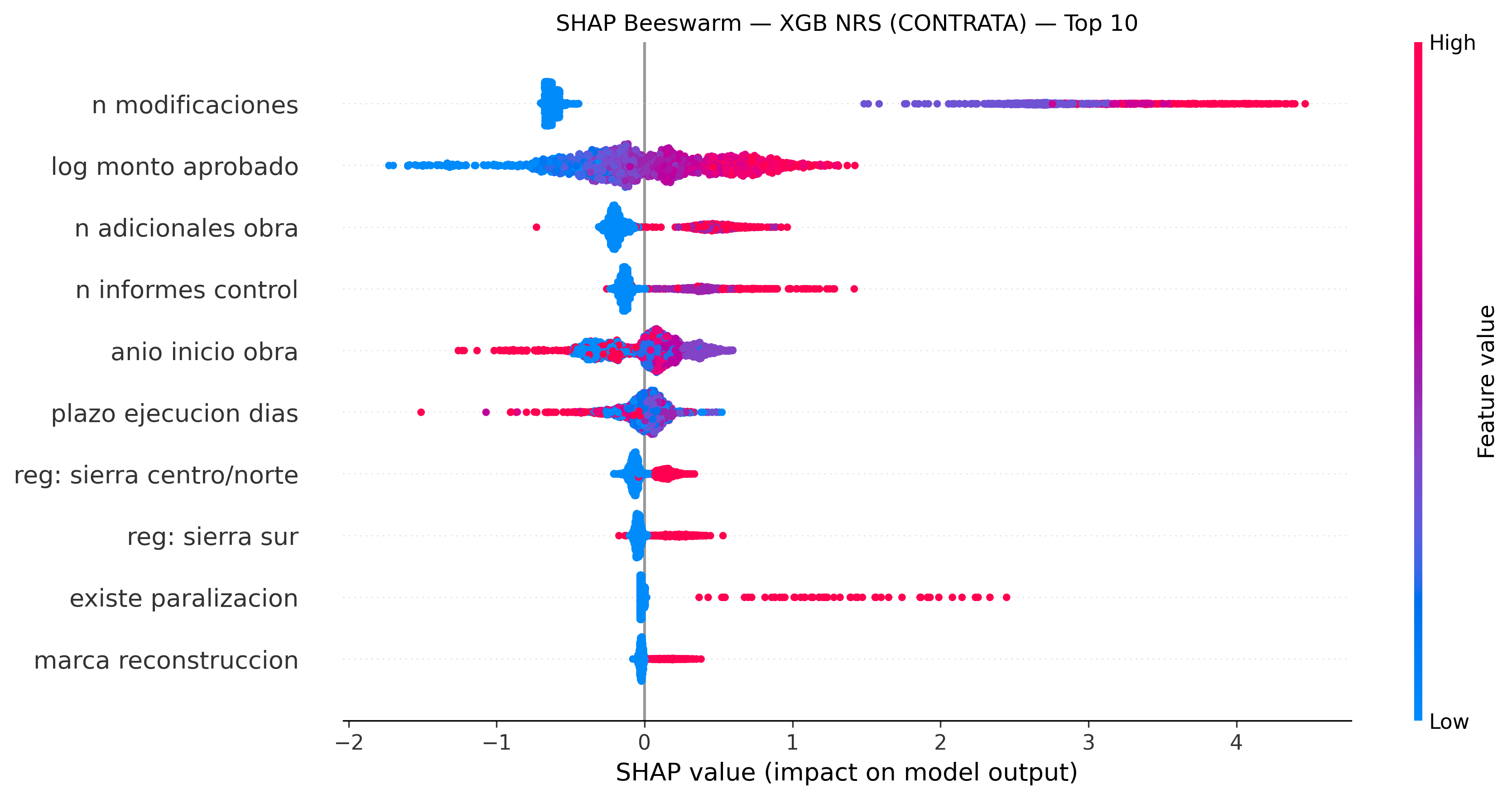
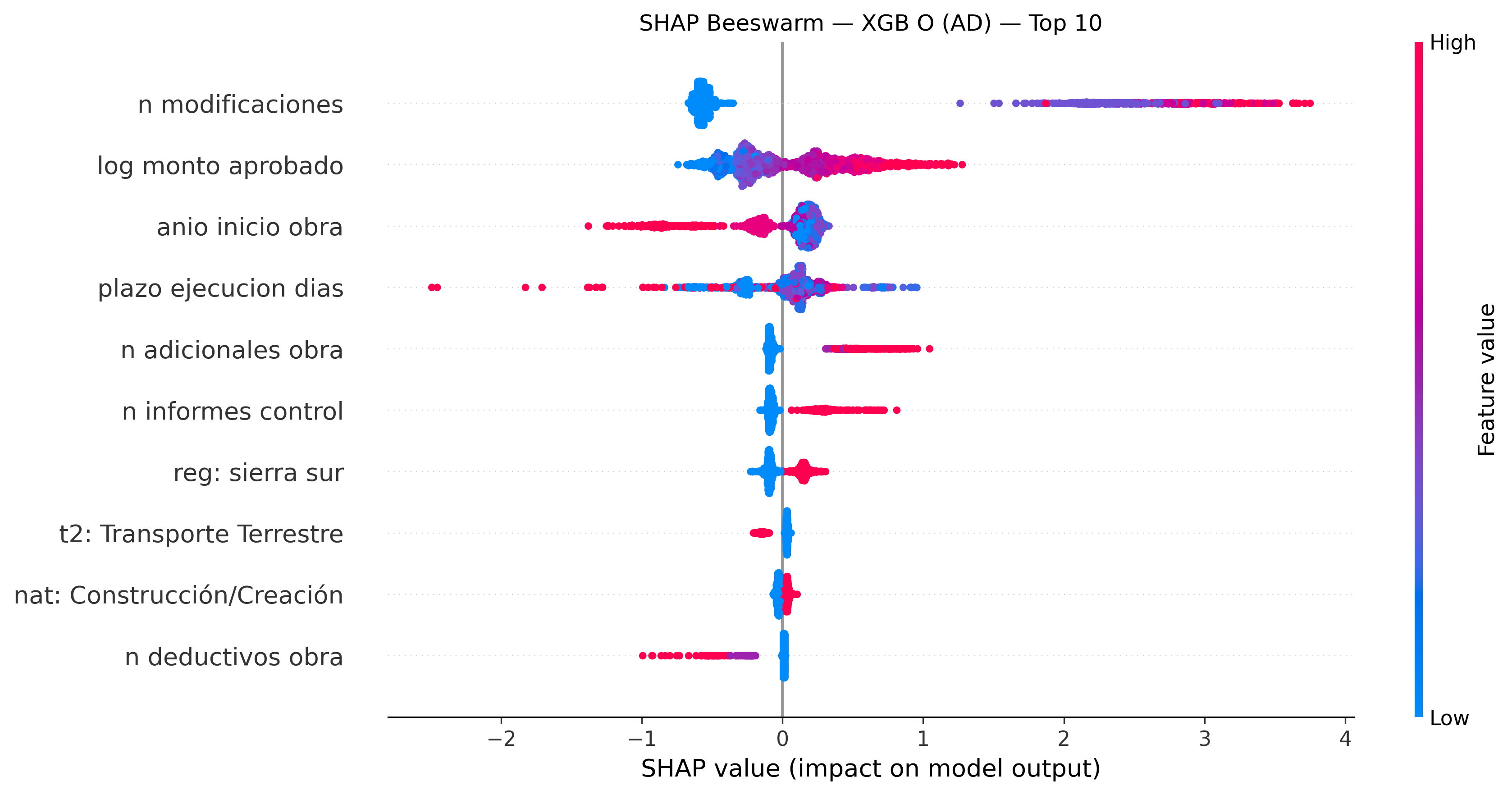
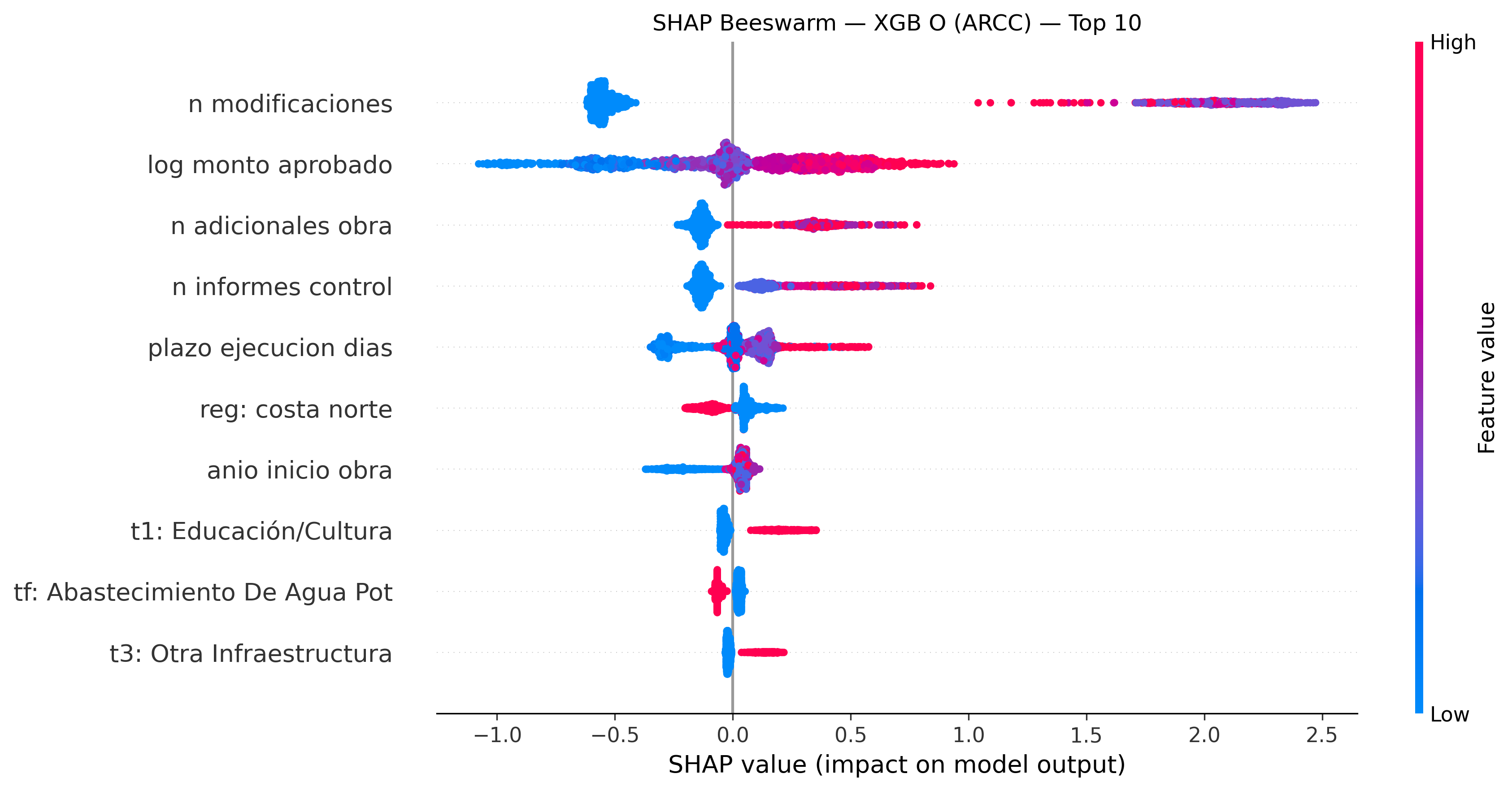
Beeswarm plots: cada punto es una observación. El eje X muestra cuánto empuja esa variable la predicción (positivo = más brecha). El color muestra el valor de la variable (rojo = alto, azul = bajo).
CONTRATA — XGB NRS
ADMIN. DIRECTA — XGB O
ARCC — XGB O
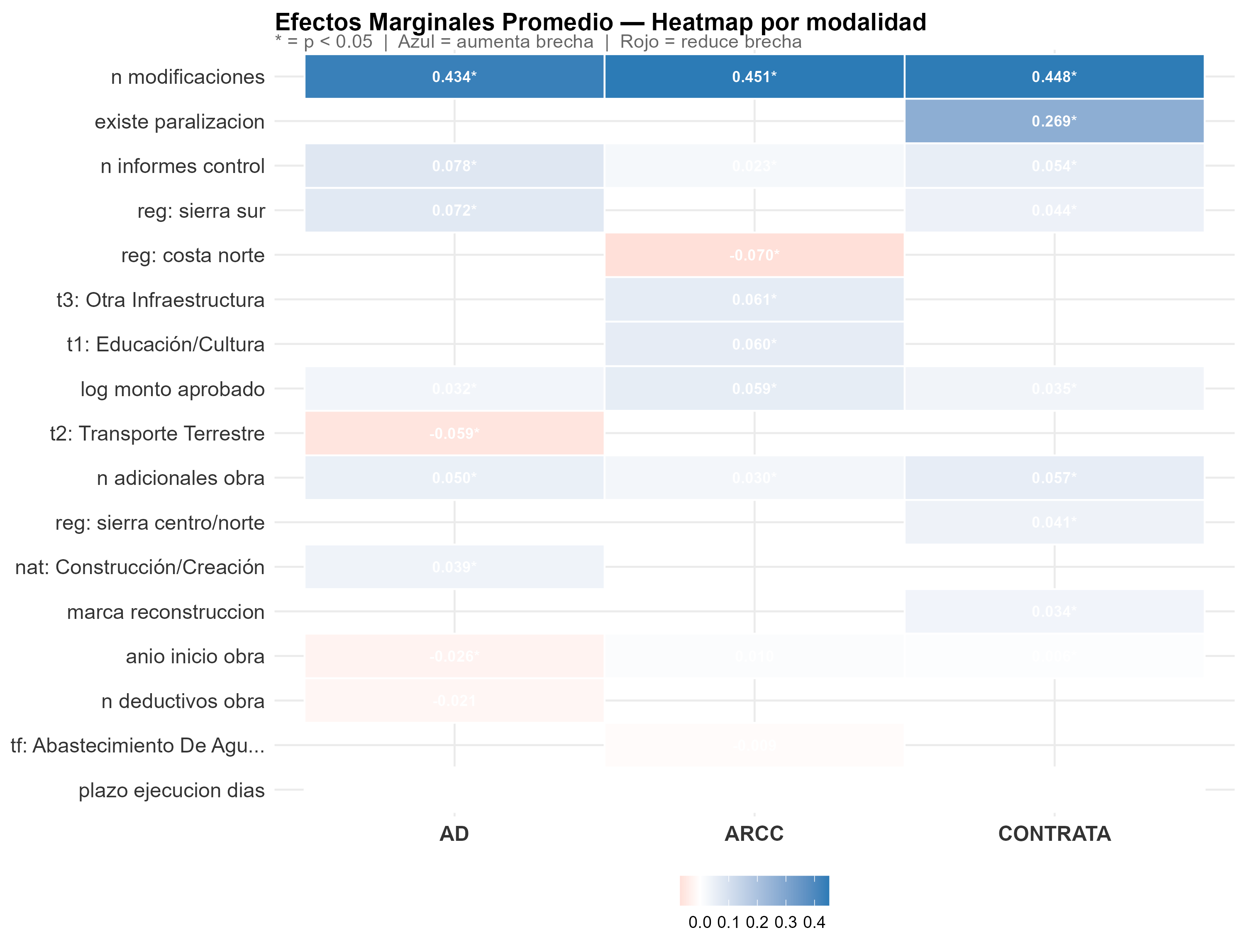
Heatmap de efectos marginales promedio del modelo logit. Azul = variable aumenta Pr(brecha). Rojo = reduce. * = p < 0.05.
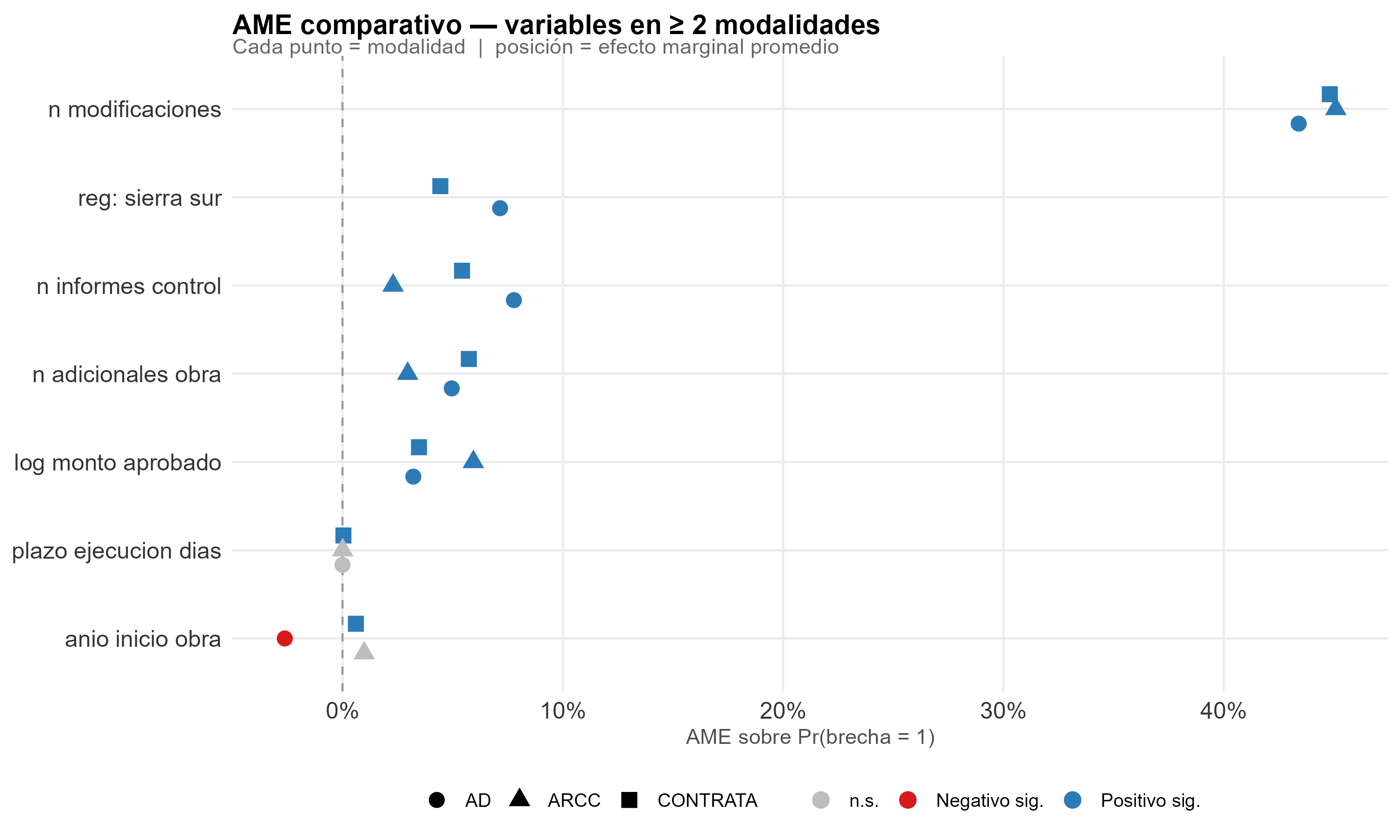
Variables comunes entre ≥ 2 modalidades:
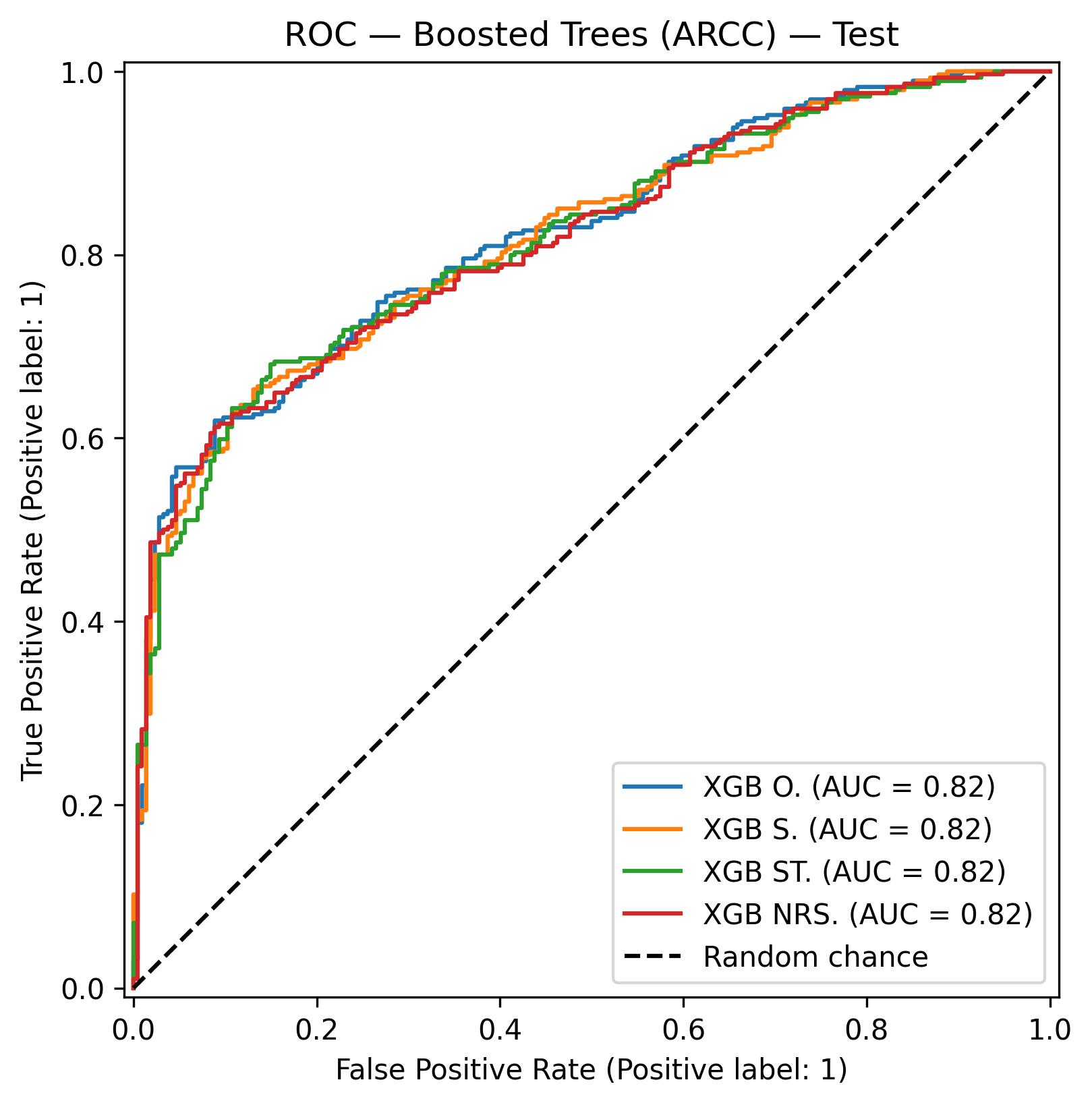
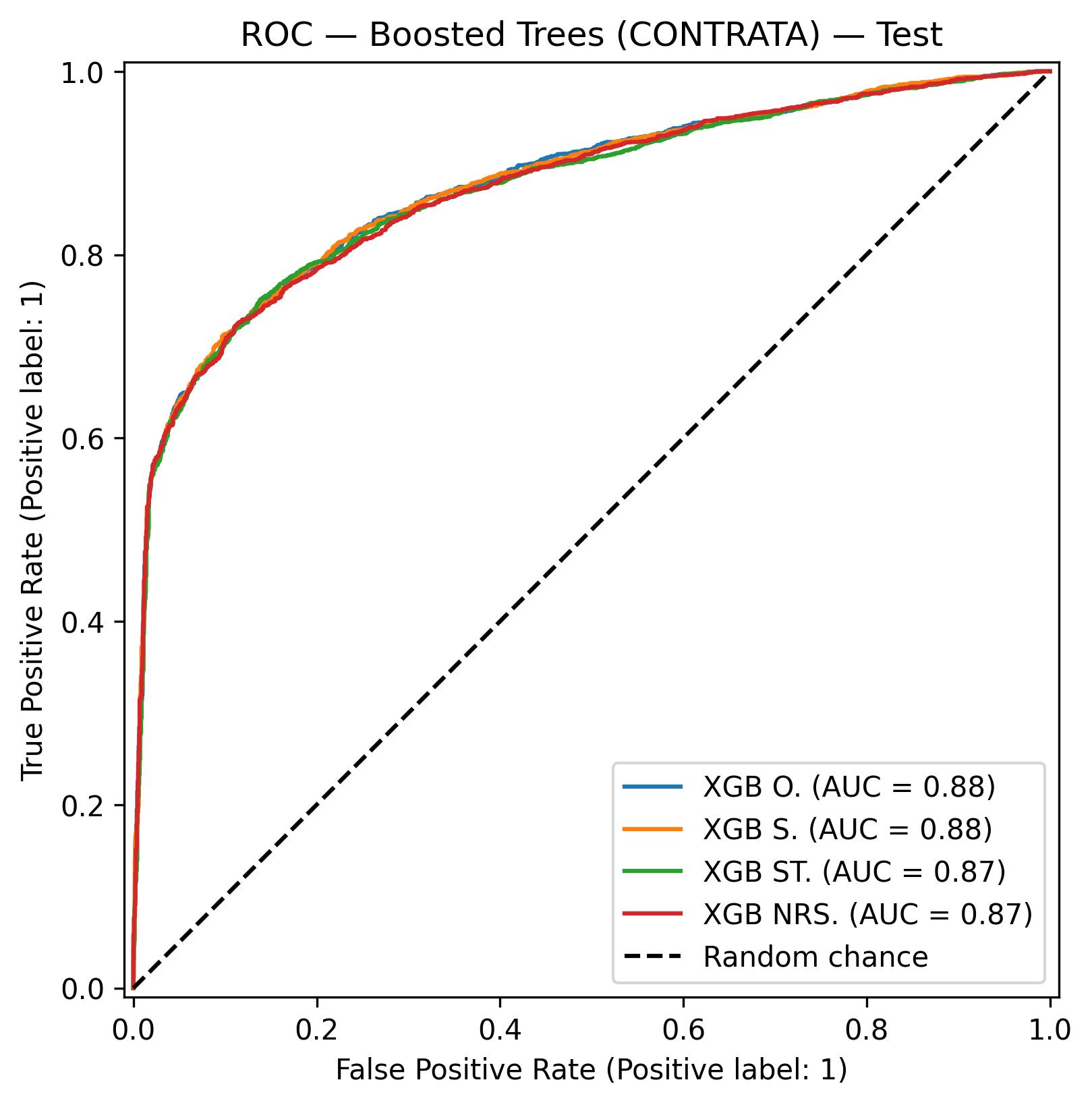
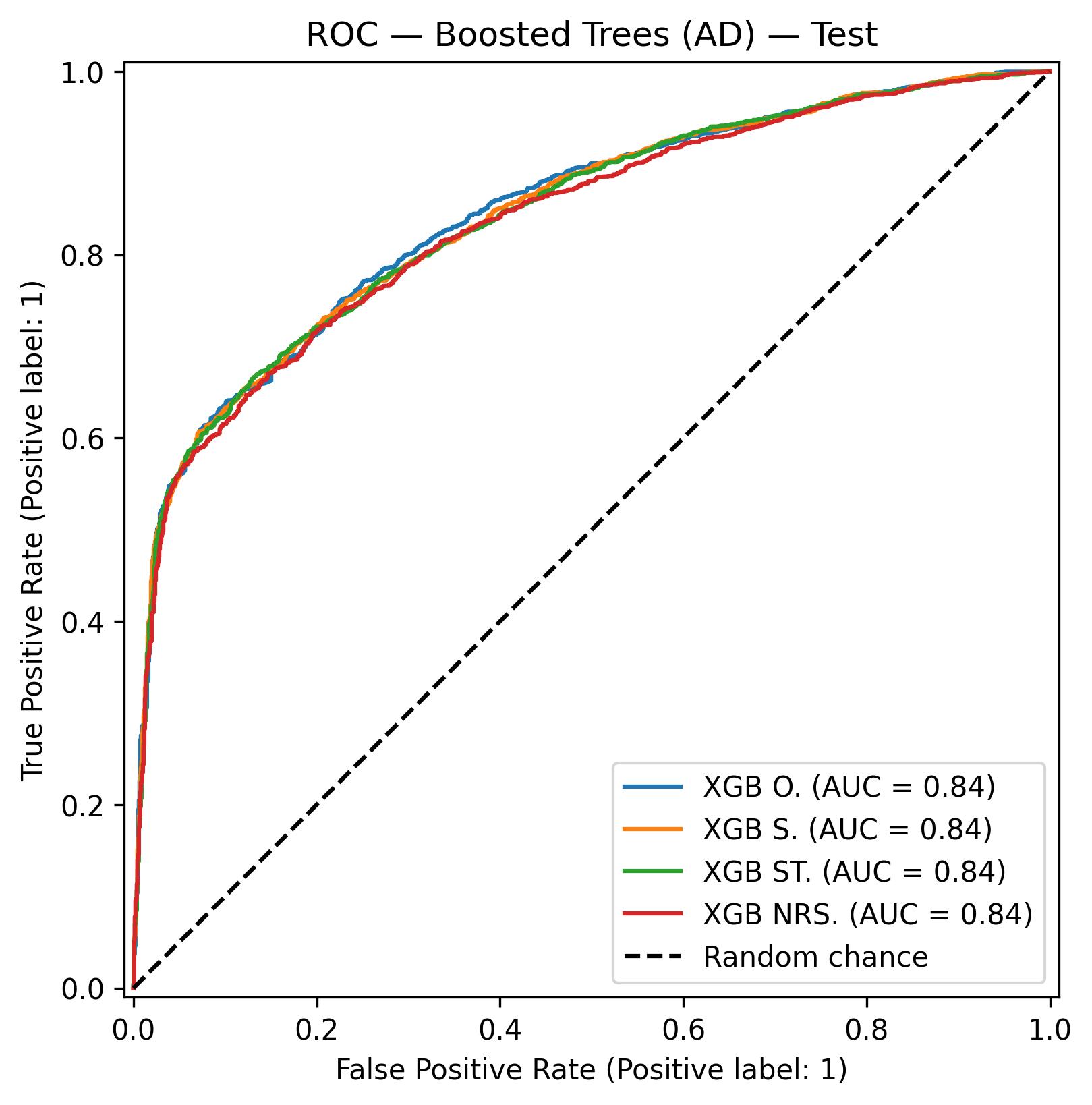
Curvas ROC del modelo XGBoost sobre el conjunto de test.
CONTRATA (AUC = 0.872)
ADMIN. DIRECTA (AUC = 0.845)
ARCC (AUC = 0.821)